[Mac/Linux] 使用 Tesseract OCR 辨識圖片中的文字
之前有試過幾種不同方法,從圖片中辨識文字 (OCR),像是:
最近又學到了另外一種,是可以在 Mac/Linux 的命令列執行的 Tesseract OCR。
下面就來嘗試一下吧~
1. 安裝 Tesseract OCR
在 Mac 上可以使用 Homebrew 安裝:
brew install tesseract
在 CentOS 上,可以使用 yum 安裝:
yum install epel-release yum install tesseract
2. 使用 Tesseract OCR 辨識文字
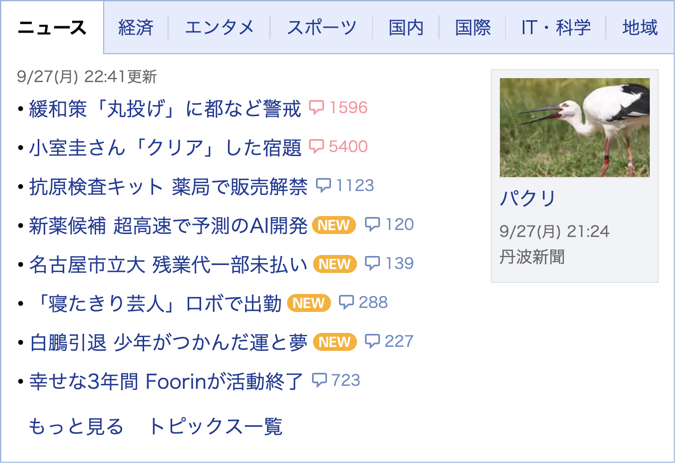
假設我們現在拿到了一張圖,裡面寫了一堆日文:
可以用 tesseract <image file> <output file> <option> 的方式執行 Tesseract。
像是我想要把 test.png 圖裡的文字,直接顯示在 console (stdout) 上,
可以這麼下:
testuser@localhost ~ $ tesseract test.png stdout =a-R @8 IVyx a2t-y BA ERR IT 5A hbae 9/27(A) 22:41 835 + BAR HRT CPREBM H 1506 WNBESA OUP) Licfe 5400 TURES y b Sea CARTER D 1123 RR BER CP ROA CED © 120 *ZABHILK REBAR 3139 + BREDBA, ONCHE S288 ° ARS DR DE ROD ACEC S CD F227 +2234) Foorind amie 7 723 both beyIZ-K NIV 9/27(A) 21:24 ALBA
不過上面的結果,好像不太理想?
原本都是日文的圖片,卻都抓出毫無關聯的英文字…
其實,這是因為沒有指定正確的語言的關係…
加上 --list-langs 來看看目前支援的語言,主要是英文 (eng):
testuser@localhost ~ $ tesseract --list-langs List of available languages (3): eng osd snum
我們可以用 Homebrew 加裝 tesseract-lang 這個套件:
brew install tesseract-lang
這樣 Tesseract OCR 支援的語言就變很多了:
testuser@localhost ~ $ tesseract --list-langs List of available languages (162): afr amh ara asm aze aze_cyrl bel ben bod bos bre bul cat ceb ces chi_sim chi_sim_vert chi_tra chi_tra_vert chr cos cym dan deu div dzo ell eng enm epo est eus fao fas fil fin fra frk frm fry gla gle glg grc guj hat heb hin hrv hun hye iku ind isl ita ita_old jav jpn jpn_vert kan kat kat_old kaz khm kir kmr kor kor_vert lao lat lav lit ltz mal mar mkd mlt mon mri msa mya nep nld nor oci ori osd pan pol por pus que ron rus san script/Arabic script/Armenian script/Bengali script/Canadian_Aboriginal script/Cherokee script/Cyrillic script/Devanagari script/Ethiopic script/Fraktur script/Georgian script/Greek script/Gujarati script/Gurmukhi script/HanS script/HanS_vert script/HanT script/HanT_vert script/Hangul script/Hangul_vert script/Hebrew script/Japanese script/Japanese_vert script/Kannada script/Khmer script/Lao script/Latin script/Malayalam script/Myanmar script/Oriya script/Sinhala script/Syriac script/Tamil script/Telugu script/Thaana script/Thai script/Tibetan script/Vietnamese sin slk slv snd snum spa spa_old sqi srp srp_latn sun swa swe syr tam tat tel tgk tha tir ton tur uig ukr urd uzb uzb_cyrl vie yid yor
現在我們用 -l jpn 參數來設定語言為日文,
再執行一次,這次就抓出了大部分的日文字,正確率還不差:
testuser@localhost ~ $ tesseract test.png stdout -l jpn ニュース | 経済 エンタメ スポーツ 国内 国際 IT・科学 地域 9/27(月) 22:41更新 ・緩和策「丸投げ」に都など警戒 1596 ・小室圭さん「クリア」した宿題 5400 ・抗原検査キット 薬局で販売解禁 1123 ・新薬候補 超高速で予測のAl開発 ヨロi20 ・名古屋市立大 残業代一部未払い 1s9 ・「寝たきり芸人」ロボで出勤 288 ・白腸引退 少年がつかんだ運と夢 Q3 227 ・幸せな3年間 Foorinが活動終了 723 もっと見る トピックス一覧 パクリ 9/27(月) 21:24 丹波新聞
下次有 OCR 的需求時,也可以試試 Tesseract OCR 這個工具囉~
參考資料:How to use OCR from the command line in Linux? – Unix & Linux Stack Exchange
(本頁面已被瀏覽過 1,624 次)